

Wraz z rozwojem aplikacji przychodzi moment, w którym zwiększa się zapotrzebowanie na dokładniejszą analizę tego, co nasz system w danej chwili robi, lub robił w przeszłości. Problem zaczyna się wtedy, gdy mamy do czynienia z architekturą rozproszoną. W takiej sytuacji, najczęściej poszczególne elementy naszego systemu znajdują się na różnych maszynach, co często utrudnia analizę występujących problemów.
Ponadto, gdy nasz system zyskuje na popularności musimy zacząć myśleć o efektywnym monitorowaniu poszczególnych jego elementów. Często, podpisujemy umowy SLA (Service Level Agreement), które wymuszają na nas pewien poziom dostępności naszych usług. Naruszenie tych umów wiąże się często z przykrymi konsekwencjami, często finansowymi. Niezapewnienie odpowiedniego poziomu dostępności nieraz doprowadzało do ruiny różne organizacje. Musimy szybko reagować na anomalie, przerwę w działaniu poszczególnych usług, kluczowe jest ustalenie przyczyny awarii i szybkie jej usunięcie.
Jednym ze sposobów monitorowania oraz ustalania przyczyn błędów w działaniu systemu jest analiza logów aplikacji i o tym opowiem w poniższym artykule.
Zastanówmy się przez chwilę, jak w prosty sposób możemy podejść do tematu organizacji logów naszego systemu. Jak wspomniałem wcześniej, istnieje duża szansa na to, że nasz system zostanie rozmieszczony na kilku (a nawet kilkuset) fizycznych maszynach. Co jeżeli, nie chcemy by zespół IT miał bezpośredni dostęp do poszczególnych maszyn? Możemy wtedy zorganizować sobie jedno miejsce, na które przekierujemy sobie nasze logi aplikacyjne, z danych serwerów i do niego dać dostęp zespołowi. Podejście to sprawdza się do pewnego momentu, niestety nie rozwiązuje ono problemu rozproszonych informacji, które dostarczają wartość przy ich całościowej analizie.
Z pomocą przychodzi ELK stack: Elasticsearch, Logstash, Kibana czyli zestaw narzędzi służący do przetwarzania logów aplikacyjnych oraz scentralizowanego zarządzania nimi. Na ELK składa się:
- Elasticsearch – baza danych, w której zapisywane będą nasze logi, zapewnia ona szybki dostęp do interesujących nas informacji.
- Logstash – narzędzie, do którego trafiają nasze logi z różnych maszyn w celu ich przetworzenia, wyciągnięcia z nich kluczowych dla nas informacji. Logstash komunikuje się z bazą danych w celu zapisu przetworzonych logów.
- Kibana – narzędzie do wizualizacji danych pochodzących z bazy danych Elasticsearch
ELK jest wydawany pod jedną wspólną wersją, oznacza to, że np. używanie Elasticsearch w wersji 6.5 wymusza na nas by pozostałe narzędzia były oznaczone tym numerem wersji.
Przyjrzyjmy się najpierw narzędziu, które bezpośrednio będzie przetwarzać nasze logi, czyli Logstashowi. Logstash umożliwia stworzenie pewnego przepływu pracy, na podstawie którego logi, które do niego trafiają mogą być przetwarzane i transformowane w jednolity sposób. Udostępnia on zestaw funkcji oraz podstawowych instrukcji warunkowych przydatnych do rozpoznawania pewnych wzorców w naszych logach oraz wzbogacania ich o dodatkowe informacje.
Podstawowym plikiem konfiguracyjnym Logstasha jest plik logstash.conf. Zawiera on trzy podstawowe sekcje, które uzupełniamy interesującymi nas wyrażeniami.
input {}
filter {}
output {}
Sekcja input definiuje wejście do Logstasha. Udostępnia ona zestaw wtyczek, umożliwiających integrację z różnymi źródłami informacji, np
- kafka – czyta zdarzenia z określonego topicu brokera komunikatów Kafka,
- log4j – czyta dane bezpośrednio z aplikacji, w której skonfigurowane jest gniazdo TCP, przez które Log4J przesyła logi aplikacyjne,
- file – służy do strumieniowania danych z pliku
Gdy mamy już skonfigurowany sposób wejścia danych, czas na ich przetworzenie. Podstawowe wtyczki dla tej sekcji filter to:
- grok – bardzo przydatna wtyczka, służąca do parsowania logów i umieszczania ich w odpowiednie pola,
- date – służy do parsowania dat, umieszczania ich w interesujących nas polach
- mutate – przydatny do manipulowania polami, konwersją danych, usuwaniem zbędnych pól
Sekcja output, określa gdzie mają trafić nasze przetworzone dane, w naszym przypadku skorzystamy z wtyczki elasticsearch, w celu zapisu naszych danych w bazie.
Polecam zapoznanie się z poszczególnymi wtyczkami dla każdej z sekcji, ponieważ jest ich dużo i każda z nich jest bardzo interesująca:
- https://www.elastic.co/guide/en/logstash/current/input-plugins.html
- https://www.elastic.co/guide/en/logstash/current/filter-plugins.html
- https://www.elastic.co/guide/en/logstash/current/output-plugins.html
Przykładowy plik konfiguracyjny może wyglądać w ten sposób:
input { file { path => “/var/log/application.log” start_position => "beginning" } } filter { grok { patterns_dir => ["./patterns"] match => { "message" => [ "%{TIMESTAMP_ISO8601:timestamp}%{SPACES}\[%{GREEDYDATA:thread}\]%{SPACES}%{WORD:level}%{SPACES}%{PACKAGE:package}%{SPACES}-%{SPACES}%{GREEDYDATA:log_message}" ] } } date { match => [ "timestamp", "YYYY-MM-dd HH:mm:ss,SSS" ] target => "@timestamp" timezone => "Europe/Warsaw" } if [level] == "DEBUG" { drop{} } mutate { remove_field => ["timestamp", "time", "host", "@version", "message", "thread"] } } output { elasticsearch { hosts => ["localhost:9200"] } }
Powyższa konfiguracja powoduje czytanie z pliku application.log, opcja beginning oznacza, że chcemy czytać plik od początku. Następnie, plik jest filtrowany, funkcja match próbuje dopasować log do podanego wzorca (powyższa konfiguracja wskazuje poprzez parameter patterns_dir miejsce ze zdefiniowanymi, nazwanymi wzorcami), a następnie przekazuje wartości do odpowiednich pól (timestamp, thread, level, package itd). Chcemy, aby nasze logi trafiły do Elasticsearch z uzupełnioną data wystąpienia w aplikacji, służy do tego wtyczka date, której podajemy format daty oraz pole do którego ma zostać przekazana. Pole @timestamp jest domyślnie wykorzystywane przez Elasticsearch i Kibanę, w celu indeksowania i wyświetlania danych po czasie. Na końcu tej sekcji usuwamy niepotrzebne pola oraz wszystkie logi z poziomem DEBUG. W sekcji output, korzystamy z wtyczki elasticsearch, więc dane trafiają już bezpośrednio do bazy.
Ostatnią rzeczą jaką potrzebujemy jest uruchomienie Kibany oraz zdefiniowanie index pattern. Jeżeli poprawnie uruchomiliśmy wszystkie elementy ELK powinniśmy mieć do wyboru interesujące na indeksy Elasticsearch.
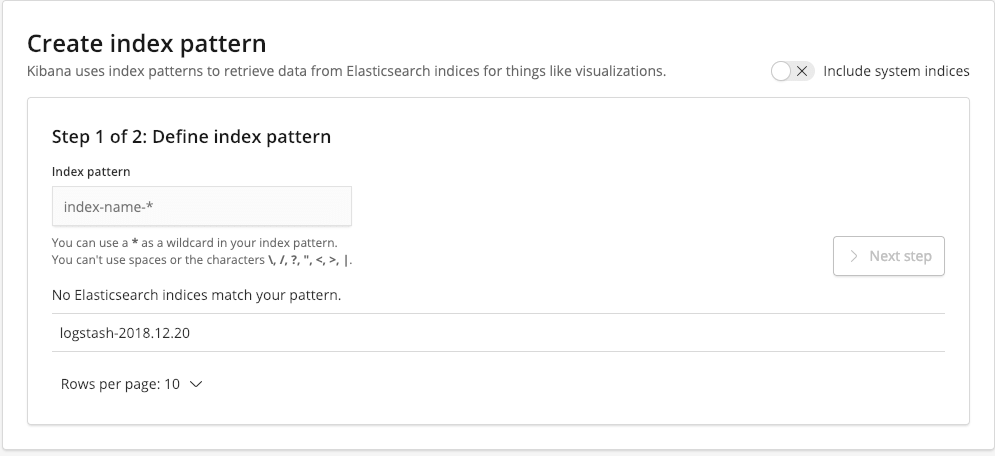
Wzorzec ustawiamy na logstash-*, przez co złapią się w niego wszystkie indeksy Elasticsearch, których nazwy rozpoczynają się od logstash-
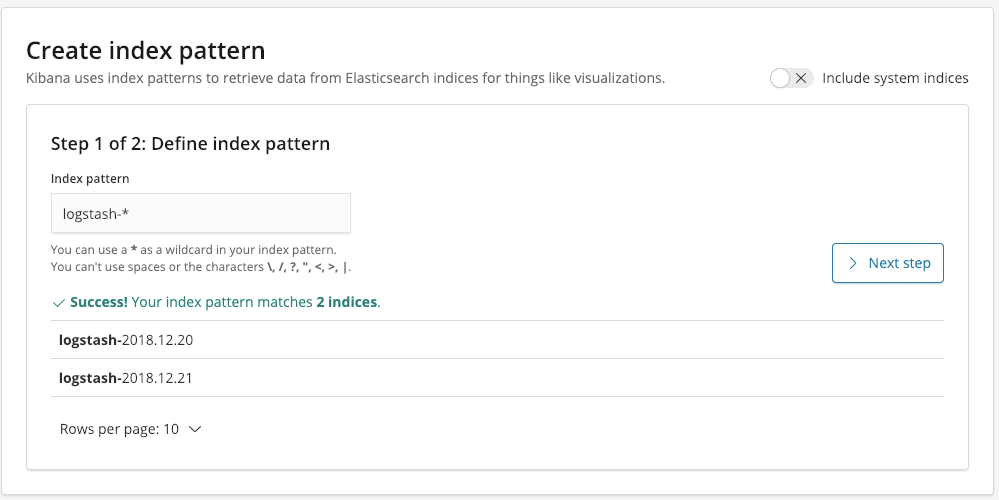
Klikamy w przycisk Next step, następnie musimy wybrać pole, które będzie służyło do filtrowania naszych danych po czasie. W naszym przypadku jest to pole @timestamp
W tym momencie możemy rozpocząć przygodę z analizą naszych danych. W celu przeszukiwania logów po zdefiniowanych wcześniej polach, przechodzimy do zakładki Discover, w bocznym menu.
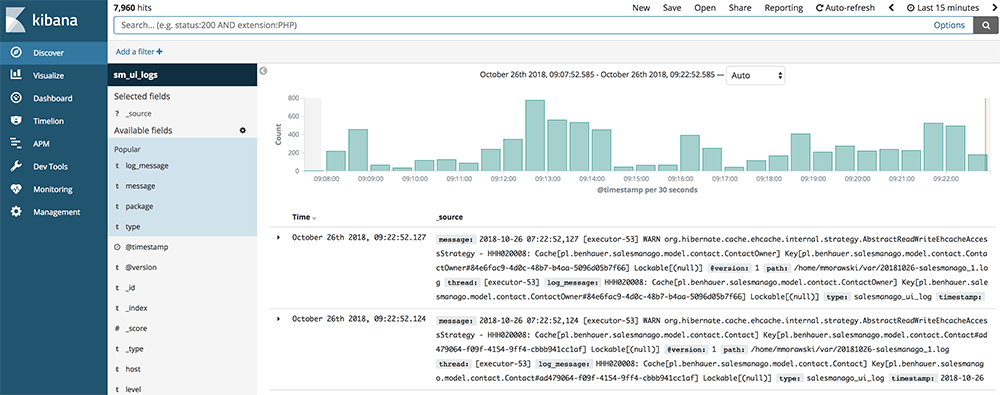
Zakładka ta pozwala na wyszukiwaniu danych, m.in poprzez definiowanie zakresu czasu, oraz wpisywaniu własnych zapytań.
Często zdarza się, że potrzebujemy skorzystać z przygotowanych wcześniej wizualizacji naszych danych. Aby przygotować takie wizualizacje, przechodzimy do zakładki Visualize. Mamy do wyboru szereg wykresów i narzędzi, które pomogą nam skorelować i zobrazować nasze dane. Do wyboru są między innymi wykresy typu line, heatmap, pie. Ciekawe jest narzędzie mapa, przydatne gdy mamy do czynienia z danymi typu IP, albo współrzędnymi geograficznymi.
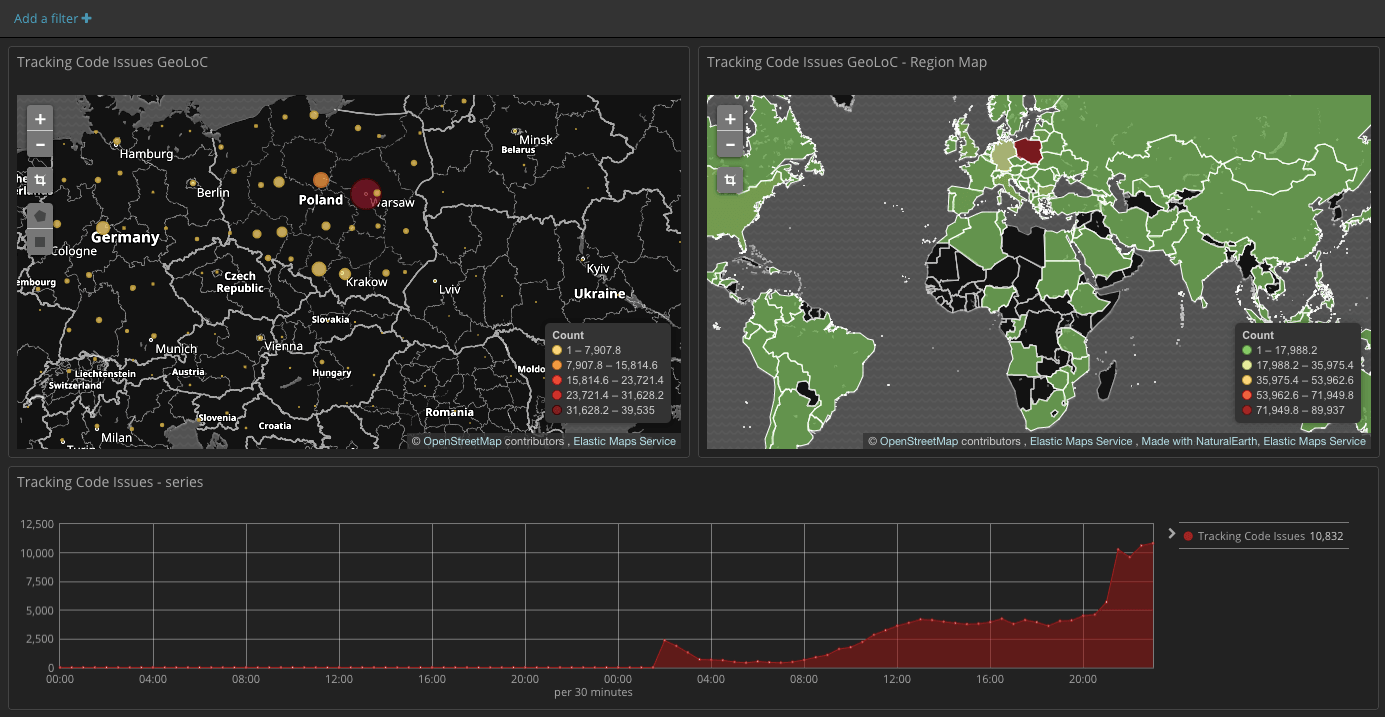
Z gotowych wizualizacji możemy budować Dashboardy, zawierające interesujące nas informacje, co bardzo ułatwia analizę zachowania naszych usług.
Od wersji 6.4 Kibana dostarcza nam również narzędzi służących do uczenia maszynowego. Oferuje on wizualizatory pomagające zrozumienie istniejących danych oraz narzędzia analizujące nasze dane pod kątem występujących w nich anomalii. Narzędzie to przedstawimy w osobnym artykule.
 Follow
Follow














![[NAGRANIE WEBINARU] „Przygotuj swój eCommerce na 2024 rok: Doświadczenia z 2023 roku, najważniejsze trendy i innowacje technologiczne dla sklepów internetowych”](https://www.marketing-automation.pl/wp-content/uploads/a-7-1-800x419.png)

![[Nowa funkcjonalność] Kreaktor Importu Kontaktów: funkcjonalna baza kontaktów bez komplikacji](https://www.marketing-automation.pl/wp-content/uploads/nf-db-nearly1-pl-800x419.png)